框架体系¶
本文档描述了Scrapy框架的各部分之间是如何相互联系的。
综述¶
图示描述了Scrapy框架和它各组件,以及内部数据在系统内如何活动(通过红色箭头表示)。 下面是对这些组件的描述,以及它们更详细的信息的链接。同时也有关于数据流的描述。
Data flow¶
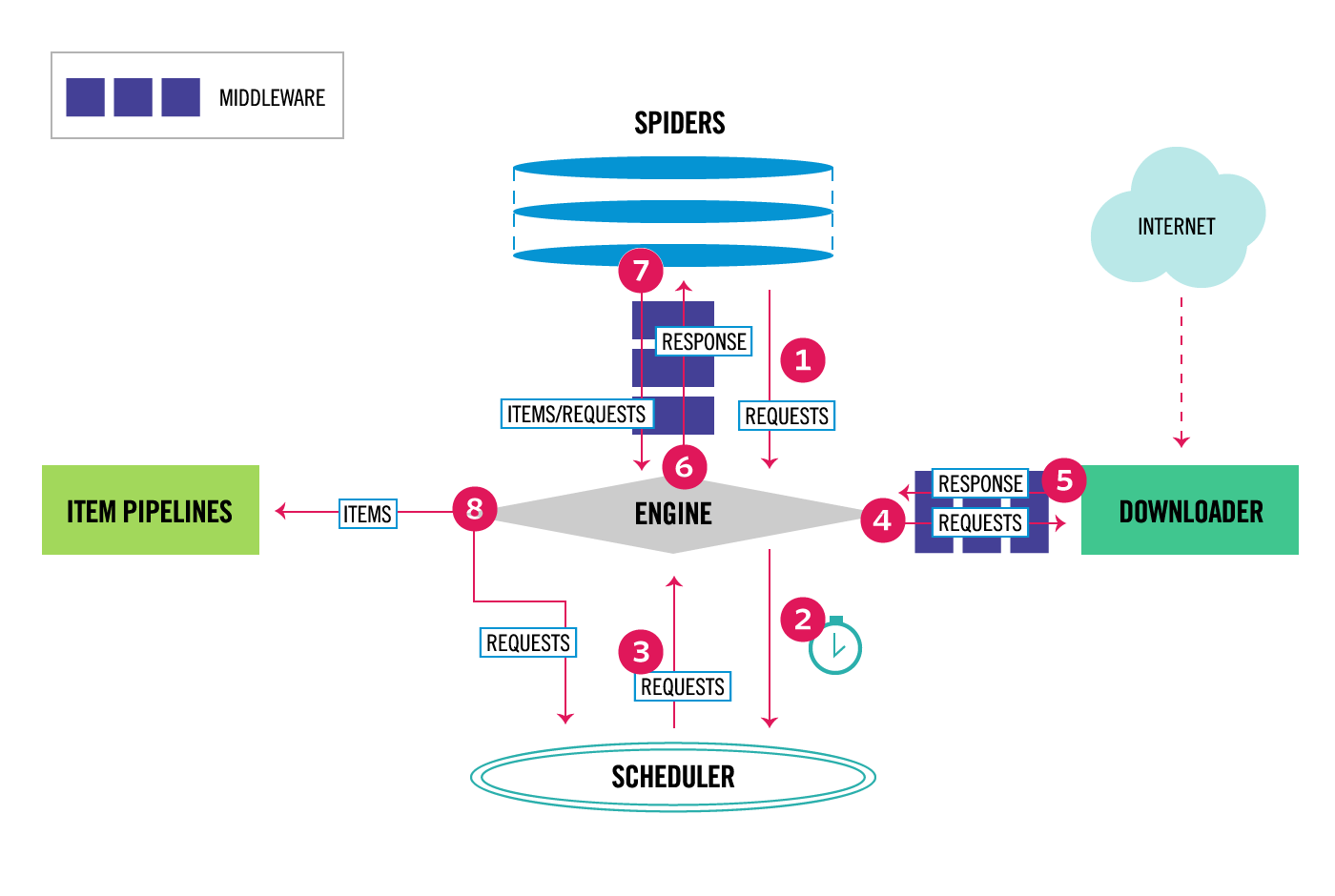
Scrapy中的数据流是由执行引擎控制的,如下所示:
- 引擎 从 爬虫器 中获取爬虫的 初始请求对象(一个或者多个)。
- 引擎 从 调度器 中调度请求对象并获取下一个要爬取的请求对象。
- 调度器 返回下一个请求对象给 引擎。
- 引擎 通过 下载器中间件 (见
process_request())将请求对象传递给 下载器。 - 一旦页面完成下载, 下载器 将生成一个响应对象(该页面的)然后通过
下载器中间件 传递给引擎(见
process_response())。 - 引擎 从 下载器 获得响应对象后把它传递给
爬虫器 使用 爬虫器中间件 处理,(见
process_spider_input())。 - 爬虫器 使用 爬虫器中间件
处理响应对象然后返回 items和新的请求对象给 引擎 (见
process_spider_output())。 - 引擎, 然后将处理过的请求对象传递给 调度器 并获得后续要爬取的请求对象。
- 这个过程(从第一步)一直重复直到 调度器 中没有请求。
组件¶
调度器¶
调度器从引擎中接收请求并给它们排序,以便于稍后引擎请求它们时将它们传给引擎。
下载器¶
下载器负责获取web页面并将它们传递给引擎,而引擎又将它们传递给爬虫器。
下载器中间件¶
下载器中间件是位于引擎和下载器之间的钩子,它处理从引擎到下载器的请求和响应。
如果你要做以下的事情,请用下载器中间件:
- 在请求到下载器之前处理它; (如: 请求发送到网站之前);
- 在响应传递到爬虫器之前改变它;
- 发送一个新的请求,而不是将接收到的响应传递给爬虫器;
- 在不获取网页的情况下将响应传递给爬虫器;
- 默默地减少一些请求。
更多细节详见 下载器中间件.
爬虫器中间件¶
爬虫器中间件是位于引擎和爬虫器之间的钩子, 能够处理爬虫器的输入(响应)和输出(items和请求)。
如果你要做以下的事情,请用爬虫器中间件:
- post-process output of spider callbacks - change/add/remove requests or items;
- post-process start_requests;
- handle spider exceptions;
- call errback instead of callback for some of the requests based on response content.
更多细节详见 爬虫器中间件.